
People exchange information via speech. The person speaking uses the mouth and vocal tract to generate a speech signal that consists of many superimposed vibrations. Depending on the linguistic content to be conveyed, the vocal tract is specifically adapted. As the vocal tract differs from person to person, the speech signals produced also differ, even if the spoken content is the same.
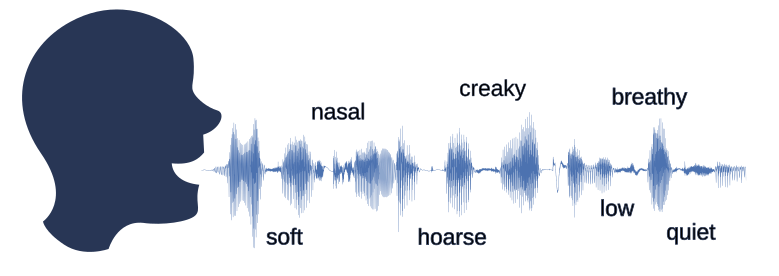
These individual differences are recorded in so-called voice qualities. Due to changes in the vocal tract, one speech signal can, for example, sound more husky or rougher than another. Phoneticians, among others, deal with such differences in speech signals. They are trained to perceive and categorise voice qualities. However, as the perception of such voice characteristics can vary from person to person, it is often difficult to teach or classify them in a standardised way.
The aim of the "Deep generative models for phonetics research" project of our "Communications Engineering" workgroup is to use generative models to generate speech signals that differ specifically only in a certain voice quality. This enables phoneticians to generate suitable stimuli that can be used to analyse or teach certain voice qualities.
In this project, a system was developed with which the speech signals of a speaker can be manipulated so that, for example, the breathiness differs, while the speaker and linguistic content remain unchanged. Here are a few audio examples. The underlying speech synthesis system has been adapted so that only the dimensions of the speaker's representation that are related to the respective voice quality are manipulated. This preserves the identity of the speaker, while only the desired voice quality changes.
In addition, the extent to which the use of such a system can support phonetic research and the training of phoneticians is being investigated.
The project will run until December 2025.
You can find out more about the project and our workgroup "Communications Engineering" here.

{kind=link}