
Menschen tauschen Informationen über Sprache aus. Dabei erzeugt die sprechende Person mithilfe von Mund und Vokaltrakt ein Sprachsignal, das aus vielen überlagerten Schwingungen besteht. Abhängig davon, welche sprachlichen Inhalte vermittelt werden sollen, wird der Vokaltrakt gezielt angepasst. Da sich der Vokaltrakt von Person zu Person unterscheidet, unterscheiden sich auch die erzeugten Sprachsignale, selbst dann, wenn der gesprochene Inhalt derselbe ist.
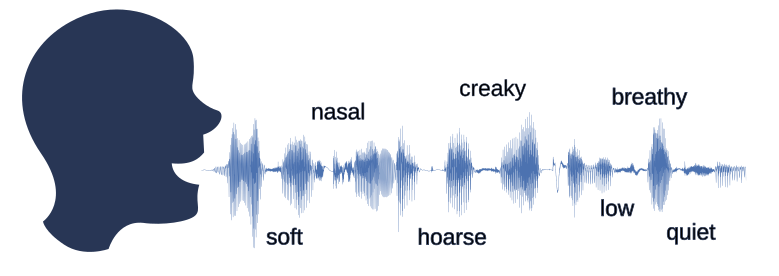
Diese individuellen Unterschiede werden in sogenannten Stimmqualitäten erfasst. Durch Veränderungen im Vokaltrakt kann ein Sprachsignal beispielsweise behauchter oder rauer klingen als ein anderes. Mit solchen Unterschieden im Sprachsignal beschäftigen sich unter anderem Phonetiker*innen. Diese sind darin geschult, Stimmqualitäten wahrzunehmen und einzuordnen. Da die Wahrnehmungen solcher Stimmeigenschaften jedoch individuell variieren können, ist es oft schwierig, sie einheitlich zu lehren oder zu klassifizieren.
Das Ziel des Projekts “Tiefe generative Modelle für die Phonetikforschung” unserer Fachgruppe “Nachrichtentechnik” ist es, mithilfe generativer Modelle Sprachsignale zu erzeugen, die sich gezielt nur in einer bestimmten Stimmqualität unterscheiden. So können Phonetiker*innen geeignete Stimuli generieren, die zur Untersuchung oder Lehre bestimmter Stimmqualitäten dienen.
In diesem Projekt wurde ein System entwickelt, mit dem sich die Sprachsignale eines Sprechers manipulieren lassen, sodass sich beispielsweise die Behauchtheit (Breathiness) unterscheidet, während Sprecher*in und sprachlicher Inhalt unverändert bleiben. Hier gibt es ein paar Hörbeispiele. Das zugrunde liegende Sprachsynthesesystem wurde so angepasst, dass nur die Dimensionen der Sprecherrepräsentation manipuliert werden, die mit der jeweiligen Stimmqualität zusammenhängen. Dadurch bleibt die Identität des Sprechers erhalten, während sich ausschließlich die gewünschte Stimmqualität ändert.
Darüber hinaus wird untersucht, inwiefern der Einsatz eines solchen Systems die phonetische Forschung und die Ausbildung von Phonetiker*innen unterstützen kann.
Das Projekt läuft noch bis Dezember 2025.
Mehr zum Projekt und zu unserer Fachgruppe “Nachrichtentechnik” gibt es hier.

{kind=link}