Benchmarking Class Expression Learning
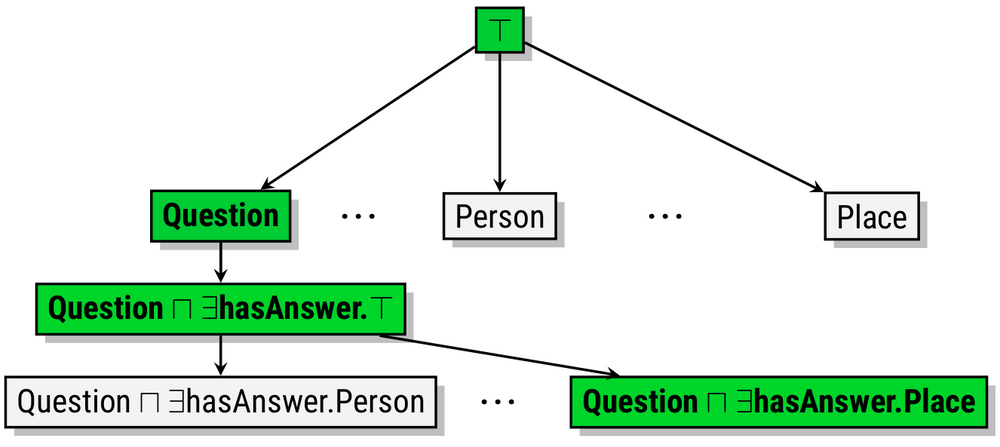
Das Lernen von Klassenausdrücken ist eine anspruchsvolle, aber wichtige Aufgabe. Bei einer Menge positiver und negativer Beispiele besteht das Ziel darin, einen Klassenausdruck zu erzeugen, der möglichst viele positive Beispiele einschließt, aber die negativen Beispiele ausschließt. Die Suche nach einem solchen Klassenausdruck findet jedoch in einem unendlichen Raum statt und kann daher recht schwierig werden. Ein klassischer Ansatz für dieses Problem ist eine Schleife, in der der derzeit beste bekannte Ausdruck ausgewählt und mit Hilfe eines Verfeinerungsoperators weiter verfeinert wird. Die folgende Abbildung zeigt einen solchen Baum von Verfeinerungen. Die grünen Knoten sind diejenigen, die für eine weitere Verfeinerung ausgewählt werden.
Die vorhandenen Benchmarks zur Bewertung der Leistung von Class Expression Learning-Algorithmen sind jedoch recht klein. Ziel dieser Arbeit ist es, einen Ansatz zu entwickeln, um einen größeren Benchmark zu erstellen. Dieser Benchmark sollte einen Wissensgraphen von der Größe von Wikidata oder DBpedia verwenden. Positive und negative Beispiele könnten auf der Grundlage von Yago- oder Wikipedia-Kategorien ausgewählt werden.