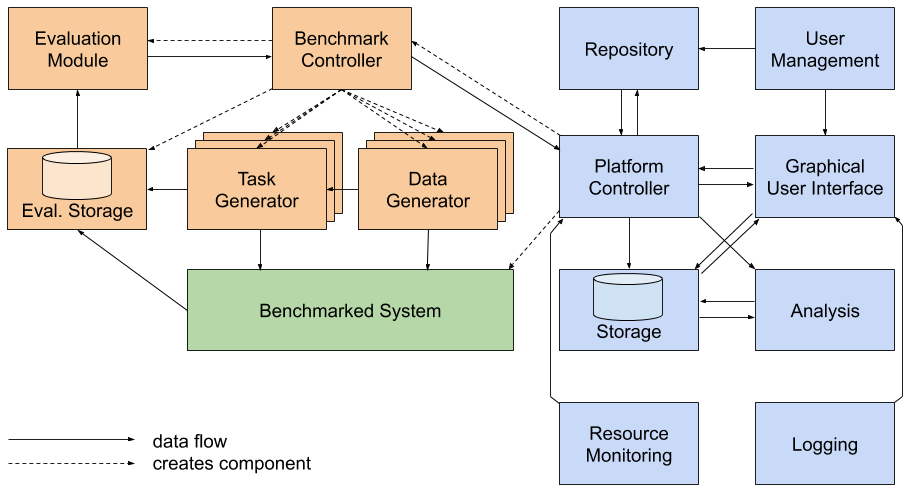
Benchmarking Linked Data processing systems
Das Benchmarking von Systemen ist für die Datenwissenschaft unerlässlich. Benchmark-Ergebnisse können die Stärken und Schwächen verschiedener Ansätze aufzeigen und als Leitfaden für die weitere Entwicklung dienen. Zu diesem Zweck sind wir daran interessiert, verschiedene Systeme mit unseren Benchmarks zu vergleichen, indem wir die uns zur Verfügung stehenden Benchmarking-Frameworks nutzen.
Es gibt verschiedene Möglichkeiten, welche Art von System im Benchmarking getestet werden kann. Ein gutes Beispiel ist das Benchmarking von Triple Stores auf unserer Big Linked Data Benchmarking Plattform HOBBIT. Die Aufgabe des Studenten ist es, ein bestehendes System (z.B. einen Triple Store) zu nehmen und einen Systemadapter dafür zu schreiben, um das Benchmarking des Systems zu ermöglichen (der grüne Kasten in der Abbildung oben). Beispiele für Triple-Stores, für die kein Adapter verfügbar ist, sind:
- TripleBit
- RDF-3X
- Tentris
- Blazegraph
- Fuseki
- GraphDB
- TriAD (verteilter Speicher)
Die Aufgabe des Studenten wäre es, den Systemadapter für den Triple Store zu schreiben. Dies beinhaltet im Wesentlichen die Implementierung der API des Benchmark/Benchmarking-Frameworks auf der einen Seite und die Implementierung der API des Systems auf der anderen Seite.
Es sollte beachtet werden, dass dieses Thema nicht auf Triple Stores und *nicht auf die HOBBIT-Plattform beschränkt ist. Sie wird nur als Beispiel verwendet. Wir haben verschiedene Benchmarking-Frameworks mit unterschiedlichen Benchmarks für verschiedene Systemtypen, die alle Schritte des Lebenszyklus von Linked Data abdecken. Dies beinhaltet:
- Wissensextraktion und ihre Unterarten (z. B. Relationsextraktion, Entity Linking usw.)
- Dreifach-Speicher
- Beantwortung von Fragen
- Faktenüberprüfung
Verwandte Projekte:
Benchmarking-Frameworks:
- HOBBIT
- Iguana
- GERBIL, GERBIL QA, GERBIL KBC